The authors are indebted to Christopher Green, Ray Fancher, Michael Friendly, Alex Rutherford, Andrew Winston and Bryn Greer-Wootten who provided invaluable feedback and suggestions on previous drafts of the manuscript.
A shorter version of this article was presented at the Annual Convention of the American Psychological Association, 2003, in Toronto, Ontario, CANADA.
Correspondence concerning this article should be addressed to Daniel J. Denis (daniel.denis@umontana.edu), Department of Psychology, University of Montana, 32 Campus Drive, Missoula, Montana, 59812, U.S.A.
Biometrician Sewall Wright introduced to genetics a procedure that would revolutionize data analysis. With the advent of Wright’s method of path coefficients in early twentieth century, the statistical landscape widened significantly. However, the adoption of Wright’s methods provoked great controversy. Essential to this controversy were claims, originally advanced by Wright, that the method could be applied to problems in which causality among variables could be assumed. In the present piece, we seek to provide an historical understanding of how path analysis became associated with causation. We begin by interpreting Wright’s early work on path coefficients, then trace key studies that utilized path analysis following Wright’s innovative contribution. By mid-century, path analysis had established itself as a causal modeling methodology and was gaining popularity in the social sciences. We conclude that today’s procedure be somewhat divorced from issues of causation, both semantically and hermeneutically.
Early multivariate statistical methods, those developed primarily by George Udny Yule and Karl Pearson in late nineteenth century, arose in part from social, political and methodological drives (e.g., see Desrosières, 1998; Porter, 1986). By 1901, Karl Pearson would lay the foundations for principal components analysis (Pearson, 1901), which would be followed by Charles Spearman’s monumental work on factor analysis in 1904 (Spearman, 1904). The factor-analytic technique pioneered by Spearman would be highly influential in the development of structural equation models in the twentieth century. The historical “parent” of structural equation modeling is path analysis1, a technique for estimating unknown parameters given a set of simultaneous equations, and of mapping out the interrelations among a pre-determined network of variables. Biometrician Sewall Wright is credited with inventing the method. Wright introduced his method of path coefficients in the context of causality and perhaps unintentionally, forever linked the statistical method with causal issues. However, path analysis and structural equation modeling2 have historically, and we argue mistakenly, become synonymous with claims of causality. For instance, many current texts on applied statistics introduce path analysis and SEM in the context of a discussion of causation (e.g., see Hair, Anderson, Tatham & Black, 1998; Pedhazur, 1997; Schumacker & Lomax, 2004; Tabachnick & Fidell, 2001). As one example, Pedhazur (1997) begins his introdution to SEM and path analysis with a thorough discussion of causation. Although he is careful to note that “path analysis is intended not to discover causes but to shed light on the tenability of the causal models a researcher formulates” (Pedhazur, 1997, pp. 769-770), we debate whether it is even appropriate to “link” path analysis with the so-called “causal model,” anymore than it is correct to associate a regression model with causation. There is simply no theoretical or philosophical justification for doing so. However, there are very strong historical reasons for why path analysis has mistakenly become associated with causation, and it is this historical account that we wish to provide. It is hoped that by providing an historical interpretation of Wright’s early work, and evaluating the work of those who followed Wright, the distinctions between path analysis and so-called “causal modeling” will become apparent, and that this discussion will help readers appreciate the historical reasons (as opposed to technical or philosophical ones) for why path analysis and SEM are often linked to issues of causation.
The article begins with a brief account of the history of path analysis as first developed by Sewall Wright during the years 1918-1921. Wright first applied path analysis to problems of inheritance. In exploring the context in which Wright first developed and employed path models, a foundation for discussing later developments and uses of the technique will have been provided. In learning of the substantive problems faced by Wright, one is in a position to better appreciate and interpret the post-Wright uses of path analysis over the course of the twentieth century. That Wright, from the outset, coined his early path models “causal,” sparked a somewhat furious debate with his rival, Henry Niles of Johns Hopkins University. The debate between Wright and Niles will be presented as to emphasize Wright’s early interpretation of his new multivariate methodology. As will be seen, the debate was dominated by Wright’s claim that the method of path coefficients could be applied to systems in which causes and effects were presumed to operate among variables. And although the debate can be said to have raised more questions than it answered, it nonetheless provides the historian of statistics with a rich source from which to interpret the methodological context in which path analysis arose. Post-Wright uses of path analysis will then be discussed. After a review of Burks’s work of 1928, an overview of work by Herbert Simon and Hubert Blalock in the 1950s and 60s will be given. It will be seen that Simon and Blalock, along with Duncan in the late 1960s, were interested in path analysis primarily in deducing “logical consequences,” to use Wright’s original phrase, of a system of variables assumed to represent a causal network. It will be argued that the causal assumptions implicit in the work of Simon and Blalock were, apart from digressions on spurious correlation, similar to those first discussed by Wright in the early 1920s. What is more, these pioneers of causal modeling appeared to be cognizant of the limitations of path analysis in making causal claims despite their popularizing it as a causal methodology. In concluding the article, it will be argued that given the history of path analysis and its current use in the social sciences, treating path analysis implicitly as a causal methodology is a breeding ground for misinterpretation and misuse. Indeed, it will be shown that current trends suggest divorcing path analysis and structural equation modeling entirely from issues of causality. Misuses and misrepresentations of path analysis center on adopting the causal semantics of Wright’s method, without, in most cases, reasonable a priori justification. It is suggested that without a “causal context” required for substantiating causal claims, path analysis is simply an enhanced and powerful statistical procedure more analogous to multiple regression, and should be interpreted void of causal verbiage.
In 1911, Sewall Wright was a graduate student at the University of Illinois studying biology. Through attending a talk on genetics delivered by William Castle of the Bussey Institution of Harvard, Wright became interested in genetics, and through the encouragement of Castle, transferred to Bussey Institute in 1912 (Provine, 2001). In 1915, Wright, now at the Animal Husbandry Division of the United States Department of Agriculture, was interested in such things as the role of genetics in the determination of color inheritance. Although by 1920 Wright had successfully used path analysis to study color transmission in guinea pigs, his very first use of path analysis occurred in 1918 in an article titled “On the Nature of Size Factors.” Using results originally published by Castle in 1914, in which correlations between various bone measurements of rabbits were obtained, Sewall Wright set out to establish a quantitative method, a method that “was designed to estimate the degree to which a given effect was determined by each of a number of causes” (Provine, 2001, p. 157). Wright’s motivation behind his 1918 paper lay apparently in response to a paper by Davenport (1917) appearing a year earlier titled “Inheritance of Stature.” Davenport’s finding was that factors contributing to the development of parts of the body were more important or “influential” in determining the stature of man compared to the body as a whole. Hence, the problem that lay before Wright was in devising a method by which one could establish the relative importance of factors in determining an outcome. His conclusion was that the body as a whole was most influential in determining differences between individuals. According to Bollen (1989), this first article by Wright was, in a sense, equivalent to a modern day factor analysis. However, nowhere in Wright’s 1918 piece was there the identification nor conceptualization of path coefficients, nor were there any path-analytic diagrams.
In 1920, Wright wrote a second article telling of the fact that he was fully engaged in the invention of a new statistical methodology. In “The Relative Importance of Heredity and Environment in Determining the Piebald Pattern of Guinea-Pigs,” 3 Wright set out to produce a quantitative model that would estimate the relative importance of heredity and environment in the generation transmission of color in the guinea pig. Early in the paper, and what will prove of utmost importance later in our discussion of causal modeling, Wright gave a subtle hint as to the methodological and philosophical limitations of what would be the method of path analysis: “As a supplement [emphasis added] to more direct attempts to determine the cause of these variations in the pattern, it seemed desirable to find the relative importance of heredity and environmental factors” (Wright, 1920, p. 321). Hence it would appear that Wright, even early in the development of path analysis, was aptly aware of its limitations in terms of making causal claims. In describing his prospective method as a “supplement to more direct attempts to determine the cause,” Wright implicitly recognized that his method was not a causal one in the sense that it could replace more traditional and philosophical modes of determining causation (e.g., Humean). With Wright’s words, one is almost left with the impression that he viewed his method as a “second choice” to more direct attempts at causation. Issues regarding causal claims in relation to path analysis will be developed more extensively later in this article.
Returning to Wright’s 1920 paper, he gave what is in all likelihood his first path diagram, that of a network of associations relating heredity and environment from parent to offspring in the guinea pig. In Wright’s diagram [Figure 1], the sire (i.e., male parent) and the dam (i.e., female parent) produced littermates having different color shades. Wright’s purpose in drawing the figure was to detail the network of determining partial influences in the production of offspring:
In a broad sense, the peculiarities of an individual are entirely determined by heredity and environment. . . . In the diagram, the pattern of each guinea-pig is represented as determined by three factors, H (heredity), E (environment common to litter mates before birth) and D (the residue, largely irregularity in development). Our problem is to determine the degree of determination by each of these factors. (Wright, 1920, pp. 328-329)

Wright’s objective was clear – to assess the relative influences of heredity and environment in the determination of color in guinea pig offspring. Wright also noted that he was working on a statistical methodology capable of addressing questions of the following genre: “In a forthcoming paper, a method of estimating the degree to which a given effect is determined by each of a number of causes will be discussed at some length” (Wright, 1920, p. 329). Although his seminal work on path analysis would be written a year after his article on guinea pigs, in 1920 Wright nonetheless provided the elementary logical foundation, as well as a generic path diagram for the method of path coefficients. He gave Figure 2 as an example in which it is hypothesized that the two quantities X and Y are “determined in part by independent causes” (Wright, 1920, p. 329). These hypothesized independent causes are given by quantities A and D. The causes B and C, as implied by the two-way arrow connecting them, are hypothesized to be correlated causes.

Wright defined the path coefficient as:
. . . measuring the importance of a given path of influence from cause to effect . . . defined as the ratio of the variability of the effect to be found when all causes are constant except the one in question, the variability of which is kept unchanged, to the total variability. (Wright, 1920, p. 329)
It is clear from Wright’s words that he wanted to measure the influence of a path that was presumed to be a causal path. That is, nowhere in the definition of a path coefficient was Wright attributing “causal power” to the coefficients, but rather, implied that if a causal assumption was made, and the direction of causation also assumed, then one could, using his method, measure the influence along the causal path. In essence, Wright posited a “closed system” in which if causal processes were established prior to analysis, one could then determine the importance of each causal path. The key to this idea lay in Wright’s following words, in which he specified, rather clearly, that if certain conditions were granted, one could determine “by implication” the coefficients along the various paths:
It can be shown that the squares of the path coefficients measure the degree of determination by each cause. If the causes are independent of each other, the sum of the squared path coefficients is unity. If the causes are correlated, terms representing joint determination must be recognized. The complete determination of X [Figure 2] by factor A and the correlated factors B and C, can be expressed by the equation:
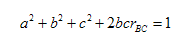
(Wright, 1920, p. 329)
Indeed, the above equation guaranteed that whatever partitioning of the causes, adding the influences must sum to unity. That is to say, in a “closed system,” such as the one considered by Wright, one could distribute the relative “weights” among possible causes. Wright noted: “The squared path coefficients and the expressions for joint determination measure the portion of the mean square deviation of the effect due to the causes singly and jointly, respectively” (Wright, 1920, p. 330). Hence, even in his preliminary work of 1920, Wright revealed the foundational ingredients to his method of path coefficients. Essentially, all Wright was doing was computing relative weights among a “system” of assumed causes and effects. The emphasis should be on “system,” since this notion would reappear repeatedly in his later work, and especially in his ensuing debate with Henry Niles. In the following, Wright further showed how his method of path coefficients was to operate in a closed system: “The correlation between two variables can be shown to equal the sum of the products of the chains of path coefficients along all of the paths by which they are connected” (Wright, 1920, p. 330). Wright then gave the following equation, showing how the closed system must achieve a desired “balance”:
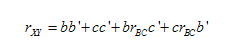
(Wright, 1920, p. 330)
The above equation reads that the correlation between variables X and Y is equal to the sum of products of various paths, as outlined previously in Wright’s path diagram in Figure 2. That is, given the relationships posited on the right-hand side of the equation, the correlation between X and Y can be quantitatively “deduced.” Following this, Wright gave the key definition of a path coefficient:
The path coefficients in a system of causes and effects can be calculated, if a sufficient number of simultaneous equations can be made,4 expressing the known correlations in terms of the unknown path coefficients . . . and expressing complete [emphasis added] determination of the effects of their causes. (Wright, 1920, p. 330)
Hence, Wright’s intention for the method of path coefficients, while not only of historical importance, is also of epic methodological importance for it held direct implications of how path analysis should be used. Wright’s outlining of a method of path coefficients can be interpreted to mean that should one be able to posit a system of causes and effects, on grounds external to path analysis, then using the correlations among variables, one could then deduce the quantities implied for each causal path. In a very real sense the simplicity of Wright’s method was that of partitioning coefficients as to satisfy mathematical rules inherent within the given system. Thus, an ideal working definition of path analysis as put forth by Wright, might be that it is a closed system in which one can study the implied relationships among variables in that system. No more, no less. The idea of causality should only enter into this definition should some or all of the implied relationships be justified as causal, on grounds external to statistical methodology. 5
As hinted by Wright, it must be assumed that the variables chosen for the model represent a “complete” causal network. In discussing the decomposition of effects, Bollen placed great emphasis on this fact: “The decomposition of effects always is with respect to a specific model. If the system of equations is altered by including or excluding variables, the estimates of total, direct, and indirect effects may change” (Bollen, 1989, p. 36). Thus, as is true of any statistical model, the estimates of effects are always only as good as the variables entered into the model. In discussing the logic of path analysis, Land (1969) emphasized, and correctly so, that the essential foundations of path-analytic logic rest on key assumptions:
In such systems of relationships, a subset of the variables is taken as linearly dependent on the remaining variables, which are assumed to be predetermined. That is, the total variation of the predetermined variables is assumed to be caused by variables outside the set under consideration [emphasis added]. . . . the given endogenous variable is ultimately determined by the exogenous variables in the system. (Land, 1969, p. 6).
There was nothing in Wright’s technical development of path analysis that made the multivariate method anything more than a tool for calculating implied coefficients6. Causality could be imputed to path analysis only if one had a causal model to begin with. We will return to issues of causality in path analysis later in a discussion of how path analysis has historically been interpreted by its adopters, mainly sociologists and economists in mid-twentieth century. Prior to this however, the reaction to Wright’s seminal work on path analysis is warranted. Published in 1921, Wright’s article would come under heavy criticism by Henry Niles, and an intense, if not somewhat malicious debate would ensue.
In 1921, Wright wrote an article titled “Correlation and Causation” in which he described more fully the aforementioned method of path coefficients. Wright began the article with an explanation as to why simple correlations were insufficient for the type of model he was considering. The following gives an acute sense of Wright’s logic in justifying the foundations of path analysis:
The ideal method of science is the study of the direct influence of one condition on another in experiments in which all other possible causes of variation are eliminated. Unfortunately, causes of variation often seem to be beyond control. . . . The degree of correlation between two variables can be calculated by well-known methods, but when it is found it gives merely the resultant of all connecting paths of influence. . . . The present paper is an attempt to present a method of measuring the direct influence along each separate path in such a system and thus of finding the degree to which variation of a given effect is determined by each particular cause. The method depends on the combination of knowledge as may be possessed of the causal relations [emphasis added]. In cases in which the causal relations are uncertain the method can be used to find the logical consequences of any particular hypothesis in regard to them” (Wright, 1921, p. 557).
Wright outlined two ways in which the method of path coefficients may be correctly employed. First, should one have presumed knowledge of the causal relations inherent in a system of variables, path analysis could be used to find “the degree to which variation of a given effect is determined by each particular cause” (Wright, 1921, p. 557). That is, if a causal system is assumed, such as was assumed in his 1920 paper on the inheritance of color, one could use the method of path coefficients to quantify degrees of assumed causality in relation to the system. A similar notion was made by Pearson and Yule in late nineteenth century (e.g., see Desrosières, 1998), in which “partial causes” of an outcome were sought. The assumption of causation in such cases must subsume the regression. For instance, if amount of welfare received is assumed to determine, at least in part, poverty status, one may denote the resulting regression coefficient as describing the partial cause of welfare on poverty. Similarly, in Wright’s earlier example of color inheritance, if one assumed that the color shade of guinea pigs is caused by heredity and environment, then one may interpret the path coefficients as assigning weight to various causal paths. A second interpretation of path coefficients was also suggested by Wright. In those situations in which causal relations were uncertain, the method of path coefficients could be used to deduce the logical consequences inherent in the system. That is, if causality could not be initially assumed to “carpet” the network of variables, then the method of path coefficients could provide, in a sense, what would be causal paths. In Wright’s sense, “logical consequences” were not equivalent to assumed causality, but rather, simply referred to path coefficient implications for various paths in a correlated system. It is clear that for Wright, issues of ontological causation were independent from the mathematics of path coefficients. Indeed, he noted explicitly that one had to assume a causal system, at least to some extent,7 before the method of path coefficients could prove most fruitful:
There are usually a priori or experimental grounds for believing that certain factors are direct causes of variation in others or that other pairs are related as effects of a common cause. In many cases, again, there is an obvious mathematical relationship between variables, as between a sum and its components or between a product and its factors. A correlation between the length and volume of a body is an example of this kind. . . . it would often be desirable to use a method of analysis by which the knowledge that we have in regard to causal relations may be combined with the knowledge of the degree of relationship furnished by the coefficients of correlation” (Wright, 1921, p. 559).
Hence, for Wright’s method to work, one must know two things: 1) presumed knowledge of causal relations, and 2) knowledge of the correlations among variables entered into the system. He implied that the method of path coefficients was most useful if causal processes could be assumed on a priori grounds.
The same year in which Wright published his seminal work on path coefficients, Henry Niles of Johns Hopkins University issued a critical reply to Wright’s work:
To find flaws in a method that would be of such great value to science if only it were valid is certainly disappointing. The basic fallacy of the method appears to be the assumption that it is possible to set up a priori a comparatively simple graphic system which will truly represent the lines of action of several variables upon each other, and upon a common result. . . . The pure mathematics by which this is shown is apparently faultless in the sense of algebraic manipulation, but it is based upon assumptions which are wholly without warrant from the standpoint of concrete, phenomenal actuality (Niles, 1922, pp. 261-264).
Essentially, Niles argued that whatever method Wright was proposing, it could not be useful since one could not establish an a priori system of causation. However, it must be emphasized that this was in no way a fault of Wright’s method. Niles’ criticism was more targeted toward the a priori grounds on which Wright’s method could be applied. That is, although Niles had no conflict with the mathematics of Wright, he vehemently disagreed with the assumption that a causal system could be initially set up and justified a priori. In Wright’s reply to Niles, he indicated, and correctly so, that the method of path coefficients proposed never claimed to address issues of concrete, phenomenal reality:
The writer has never made the preposterous claim that the theory of path coefficients provides a general formula for the deduction of causal relations. He wishes to submit that the combination of knowledge of correlations with knowledge of causal relations, to obtain certain results, is a different thing from the deduction of causal relations from correlations implied by Niles’s statement. Prior knowledge of the causal relations is assumed as a prerequisite [emphasis added] in the former case. Whether such knowledge is ever possible seems to be the subject of Niles’s philosophical discussion of the nature of causation. (Wright, 1923, p. 240).
In essence, the debate between Wright and Niles was simple. Wright put forth a method by which if a causal system could be at least provisionally assumed, then the logical consequences of the system could be found by applying the mathematics of path analysis. Niles’s objection lay more with the assumption of obtaining a group of variables for which one could consider it a “causal system.” He contested not with the mathematical details of Wright’s analysis, but only with the substance to which the method of path coefficients could be applied. Indeed, in a later reply by Niles, he made it clear that he debated only with the assumptions required for path analysis, and not with the mathematics of the procedure: “I have never attacked the mathematics of the method of ‘path coefficients’ because it seems sound enough when the preliminary assumptions regarding the basis of the method are granted, [original italics] but I do not grant them” (Niles, 1923, p. 256). For Niles then, the method of path coefficients was simply incompatible with notions of scientific causation.
The debate between Wright and Niles ended in a truce, that is, in agreeing to disagree. In a postscript to Niles’s last reply, Wright noted: The opportunity has courteously been given the writer of seeing Mr. Niles’s counter-reply. As it appears to him that an adequate answer to all of the points which Niles raises may be found on careful reading of his present paper, he is willing to rest his case at this point” (Wright, 1923, p. 255). Hardly a declared winner. Indeed, even now, it is of some difficulty to choose a true victor of the debate. As remarked by Meehl and Waller:
Path analysis, whatever its ultimate fate, will present historians and philosophers of science with a puzzle. Ever since Sewall Wright’s classic (1921) article and the ensuing exchanges with his critic, Niles . . . there has been sharp disagreement about the method’s value. . . . Today, after three generations of discussion by statisticians, psychologists, sociologists, and philosophers of science, the disagreement still seems about as great and insoluble as in the Wright-Niles exchange. (Meehl and Waller, 2002, p. 283)
The question naturally arises as to how and what to make of the Wright-Niles exchange. Although at the heart of the debate seemed to be fundamental differences of opinion regarding correlation and causation, it seems safest to conclude that their disagreement was more about the types of systems path analysis could be applied to, rather than the actual mathematics. For Niles, such causal systems as proposed by Wright could not be assumed and then analyzed by the mathematics of correlation. For Wright, if one assumed an underlying causal process, an assumption apparently attainable in his field of work (i.e., genetics), the method of path analysis could be useful. For the purposes of the present article, it is of little benefit to choose sides of the debate. Rather, it is important only to appreciate the general theme of their disagreement, as it will help to clarify and contextualize later interpretations and uses of path analysis in twentieth century.
One benefit of studying the history of multivariate statistics is that it allows one to revive the context in which a multivariate method arose, along with the social and methodological problems that it originally sought to solve. A second advantage is that it grants the historian a vantage point from which to interpret and evaluate the evolution of a method since its time of inception. In this regard, the historian of statistics is able to critically evaluate and appraise modern uses of a multivariate tool by comparing its present-day use to its original aim at its time of inauguration. The method of path analysis is especially well-suited for this type of historical treatment. In studying the evolution of path analysis and its scope of application across the social sciences, it will become apparent that there are striking dissimilarities between the path analysis performed by Wright and how many path models are interpreted by modern social scientists. True that the mathematics of the procedure have remained relatively constant, the “species” of problem to which path analysis is now applied varies greatly from Wright’s initial projects. Moreover, by interpreting the work of Wright’s original analyses, one is then in an ideal position to evaluate whether his “methodological theme” has been maintained over the course of the twentieth century. Unlike the analysis of variance, in which Fisher described it simply as a way of “arranging the arithmetic” (Fisher Box, 1978, p. 109), for Wright, path analysis was to be used for much more than simply partitioning correlations and estimating coefficients along various paths. Rather, Wright intentionally advertised his method as one to be used for causal systems, that is, systems for which there were strong grounds for presumed causation within the given hypothesized network.
In what follows, it will be argued that causal modeling arose more from a “genre” of problem, rather than independently as a statistical procedure. The distinction is an important one. For instance, in texts on multivariate statistics, chapters devoted to “causal analysis” often appear separate from chapters on regression analysis (e.g., see Pedhazur, 1982).8 It will be argued that the presentation of causal analysis as a distinct methodology leads to undue confusion and to misguided interpretations and applications of multivariate path analysis. Of course, the majority of social scientists, if given the choice, would naturally choose a method advertising a “causal conclusion” over one subsumed under the unappreciated name of “regression.” Hence, it is of interest to trace the interpretation of path analysis by those who immediately followed Wright’s original work. Despite the increasing coining of the phrases “causal modeling” and “causal analysis” over the course of the twentieth century, as will be seen, there appears now to be a growing consensus among writers that “causal modeling” is not causal whatever, and issues of causation should be considered entirely independent from the method of path coefficients. Given the growing trend to consider path analysis and structural equation modeling as non-causal, a question that needs to be addressed is whether using path analysis in such a way violates its original aim set out by Wright. It will be concluded that given the correct variables, causation can be assumed just as well under the heading of regression as it can under the name of path analysis. In this sense then, the “causation” historically associated with path analysis must be entirely abandoned.
According to Wolfle (2003), the first use of path analysis post-Wright was in 1928 by Burks in a study by the name “The Relative Influence of Nature and Nurture Upon Mental Development: A Comparative Study of Foster Parent-Foster Child Resemblance and True Parent-True Child Resemblance.” This work appears to be the first use of path analysis in psychology. 9 Burks’s investigation sought to determine the relative influences of parental intelligence and environment in determining the I.Q. of children. She drew the diagram in Figure 3 showing the structural flow of her study.

Careful reading of Burks’s work reveals that while using Wright’s method of path coefficients, she did not unduly emphasize grand claims of causality in her substantive conclusions. Burks wrote: “This situation is a particularly favorable one for using the Wright technique, for the assumptions regarding casual relationships are here at a minimum” (Burks, 1928, p. 300). What Burks meant by “casual relationships” was the absence of unanalyzed relationships (i.e., correlations). In a footnote to her presentation of the path model, Burks revealed what we hold to be the correct interpretation of path coefficients, and supports the idea that causation should be considered independent of statistical method. Burks:
The method [of path coefficients] is limited by the rarity [emphasis added] with which we have actual knowledge of causal relations; but it provides a tool of the nicest precision in such situations as do offer an adequate basis for postulating causation. It cannot, itself, uncover what is cause and what is effect, though in the absence of definite knowledge regarding causal relationships between variables, the method ‘can be used to find out the logical consequences of any particular hypothesis in regard to them.’ Conservatively stated, in any situation in which we feel justified in drawing conclusions regarding the effects of certain phenomena upon others, the Wright method provides a numerical expression of such conclusions (Burks, 1928, p. 299).
Burks’s interpretation of path analysis was correct. In the above footnote, she showed a clear understanding of the method’s limitations, while also cognizant that it was a powerful method given “justification” of presumed causes and effects. Neither was Burks foolish enough to make grandiose claims of causation. Indeed, she interpreted path coefficients as regression-like numbers: “a represents the direct path of influence between parental intelligence and child’s I.Q. and a 2 the percentage of I.Q. variance attributable to parental intelligence” (Burks, 1928, p. 300). In terms of implying a causal process, Burks did so, but gently, as to imply only directionality of the processes inherent in the path model: “The directions of the arrows indicate the relationship of the variables with respect to cause, effect, and possible reciprocal action” (Burks, 1928, p. 300). With this last statement, Burks simply implied that it was assumed that parental intelligence contributes, as a partial cause, to the intelligence of children. Indeed, even in simple regression terms, and perhaps with some coaxing, even the most anti-causation advocate would at some point concede that there is an underlying presumed causal process (genetic or otherwise) from parental intelligence to children’s I.Q.10
There is a lesson to be learned from the first post-Wright use of path analysis in an applied setting. Burks, we argue, used Wright’s method correctly, and drew careful and cautious substantive conclusions from it. She clarified the limitations of Wright’s method in terms of causation, and in a single footnote, literally divorced the method of path coefficients from issues of philosophical causation. Her only reference to causality was to assume it as part of her model and to hypothesize directionality amongst the variables in her network. Indeed, had Burks wanted only to trace the influence of parental intelligence on children’s intelligence excluding the influence of environment, a simple regression analysis would have been more than sufficient, and she would have not needed to change her causal assumptions in the least. That is, it is clear from Burks’s work that she paid due attention to Wright’s original teachings. Path analysis was simply a technology that was “advertised” for causal systems, and nothing more. Burks’s complete work of 1928 could indeed serve as a brief tutorial on the correct use of path analysis as applied to social data.
The next “era” of path analysis began almost 30 years after Burks’s study on intelligence. The method was initially adopted by sociologists and economists within the wider social science environment. It is questionable whether the value of Wright’s work was ever fully recognized by early sociometricians and econometricians in mid twentieth century. As will be seen, Wright’s early work seems to have been given only passing notice by Blalock in his highly influential book Causal Inferences in Nonexperimental Research11 appearing in 1964. A year prior to Blalock’s work, an article by Duncan and Hodge (1963) represented the first empirical study of the new path-analytic era (Wolfle, 2003). Their study concerned relating factors of education and occupational mobility. As will be seen, the nature of these early sociological models was such that making causal assumptions was more “justified” than the causality often assumed by modern psychological investigators. As will also become apparent, path analysis, employed as causal modeling, usually comes pre-packaged with key assumptions that could arguably never be satisfied in practice. For an understanding of what these assumptions are, and how they are virtually impossible to satisfy in real-world research, it is first necessary to review the work of Herbert Simon and the concept of spurious correlation.
Herbert Simon (1916-2001), a self-declared mathematical social scientist, wrote Models of Man in 1957. Simon generally believed that the social sciences needed a rigor and underpinning comparable to that found in the hard sciences. In chapter two of Models of Man, Simon asked the following question: “Are there any operational means for distinguishing between true correlations, which do imply causation, and spurious correlations, which do not (Simon, 1957, p. 37)?” Noting that Yule (see Yule & Kendall, 1932), among others had previously examined notions of spurious correlation, Simon defined it as: “the clarification of the relation between two variables by the introduction of a third. . . . In investigating spurious correlation we are interested in learning whether the relation between two variables persists or disappears when we introduce a third variable” (Simon, 1957, p. 37/39). The clarification sought by Simon were the conditions under which a correlation between two variables provided a basis for inferring causality. As such, we have in Simon a first attempt to deal with causal issues by statistical manipulation rather than solely on a priori grounds. However, as will be seen, despite implying ideas of statistical causation, Simon too could not escape the deep assumptions required for an adequate causal model. A simple example of spurious correlation in path models now follows.
Consider the path diagram in Figure 4, denoting a simple bivariate relationship between two observed variables X1 and X2. Ru and Rv represent respective error terms for each variable. That is, Ru and Rv represent variation unexplained by X1 and X2. The model hypothesizes that X1 causes X2. At this point, even without a third variable in the equation, Simon argued that one could make preliminary assumptions about causation if certain conditions were satisfied.12 For instance, if the directionality of causation could be assumed a priori, such that X1 causes X2 and not the reverse, the first assumption necessary for causality could be said to be satisfied. The second and more difficult assumption, if not wholly unrealistic, was that the errors13 associated with X1 and X2 are uncorrelated. That is, the correlation between Ru and Rv must be assumed to be zero. Substantively, this would require there to be no other variables in the universe correlated jointly with X1 and X2. The assumption is, of course, unlikely to be satisfied in practice. Should these two assumptions be satisfied however, the path from X1 to X2, according to Simon, could be interpreted causally.

Adding a third variable to the bivariate model, the goal then becomes one of learning whether the pre-existing correlation between X1 and X2 can be explained by the third variable, and hence provide support of a spurious relationship hypothesis between X1 and X2. Should the correlation between X1 and X2 remain constant, then it could be assumed that the relationship is non-spurious. For instance, if a third variable is entered into the model, and the correlation between X1 and X2 disappears (i.e., goes to zero), this would constitute evidence of a spurious correlation between X1 and X2. If it does not disappear, and provided the previously noted assumptions (i.e., directionality and uncorrelated error terms) are granted, the relationship between X1 and X2 could still potentially be causal and non-spurious. 14
It is essential to note that even in this last case of the three-variable model, substantive conclusions are only as good as the assumptions entering into the model. For instance, assumptions of the causal ordering (i.e., directionality) of variables is of vital importance in proposing any given model. It can be argued that this assumption is more easily “justified” in some research contexts than in others. For instance, if we assumed age to cause health problems, we could be relatively confident in positing a directional relationship from age to health. That is, since most would undoubtedly agree that one’s health cannot determine one’s chronological age, any hypothesized relationship, other than an unanalyzed one (i.e., correlational), must be from age to health. Indeed, Wright specifically identified biology as a field in which directionality of causes was rather implicit: “The biologist . . . is to a large extent concerned with variables which at his level of observation are related in irreversible sequence. . . . Our technique of interpretation of statistical systems must then take account of sequential relations” (Wright, 1931, p. 156). Further, as will be discussed later, the path analysis as adopted by sociologists in mid-century often made similar assumptions of directionality and temporal sequence.15 The second assumption, as noted earlier, and listed by Simon under “a priori assumptions” in Models of Man, was that the errors of the variables are uncorrelated: “’all other’ variables influencing x are uncorrelated with ‘all other’ variables influencing y, . . . it must be emphasized that these assumptions are ‘a priori’ only in the sense that they are not derived from the statistical data . . . the assumptions are clearly empirical” (Simon, 1957, p. 12). Again, it is highly unlikely this assumption could ever be satisfied in practice. In essence, as Wright did almost 40 years earlier, one has to posit a “closed system” for which the assumed causes are somehow known and equally accounted for in the given model under consideration. Recall that it was exactly on such grounds that Niles rejected the method of path analysis in totality.
Sociologists16 were likely the first academic group to adopt path-analytic methods to disciplines other than genetics. Hubert M. Blalock (1926-1991), in Causal Inferences in Nonexperimental Research, published in 1964 and considered a “classic” in the sociological field, furthered the work of spurious correlation initially begun by Simon17. In Causal Inferences, Blalock outlined methods for making causal inferences from correlational data along with outlining problems in confirming these relations. What is perhaps most relevant in Blalock's work as concerns the context of causal modeling, is that he made explicit that whatever relationships or mathematical deductions are entertained in non-experimental data,18 the “license” to claims of inferring causality in these models must be purchased wholly from a priori assumptions. Beginning with Simon’s notion of “models,” Blalock wrote:
In view of the general nature of the problems encountered when we attempt to bridge the gap between theory and research, Simon’s proposal seems quite sensible. However, it will probably be extremely difficult for most persons, including the present writer, to get along without the aid of a metaphysical assumption to the effect that something akin to causal laws operates in the real world and not just in the hypothetical models of the scientist. But such an assumption amounts only to a “pious opinion” and cannot be demonstrated by any methods presently known (Blalock, 1964, pp. 14-15).
In Blalock, we have a sociometrician interested in establishing causation among variables, but also keenly aware that pursuits of causation are literally laden with assumptions prior to statistical modeling. What is more, he placed great emphasis on the prior theorizing that is central to using causal analytic methods: “We must start with a finite number of specified variables. . . . a good deal of thought and research would be necessary prior to the decision as to exactly which variables to include in the system. . . . once having made this decision, we must confine ourselves to these explicit variables” (Blalock, 1964, p. 15). Hence, recalling the “closed system” assumption remarked earlier in the work of Wright, Blalock, even if optimistic about possibilities of inferring causation from nonexperimental work, nevertheless appreciated the assumptions required for causal models to be even remotely “equal to their name.” Indeed, in the conclusion of Causal Inferences, Blalock wrote:
Causal inferences belong on the theoretical level, whereas actual research can only establish covariations and temporal sequences. . . . we can never actually demonstrate causal laws empirically. This is true even where experimentation is possible. Causal laws are working assumptions of the scientist, involving hypothetical statements of the if-then variety. . . . Included among the if’s of causal assertions is the supposition that all relevant variables have been controlled or can safely be ignored. This kind of assumption can never be tested empirically (Blalock, 1964, pp. 172-173).
Hence, from Blalock, we get a strong “reality-check” regarding the scope of causal analysis – it is only as substantively meaningful as the causal assumptions that go into it. His work also helped put into perspective the work of Simon, in that while spurious correlation may be useful, identifying all possible third-variables19 that might account for a given bivariate relation was next to impossible, and hence lent to great difficulty in confirming causal claims. Indeed, it would appear that influential sociometricians of the time recognized this limited scope, yet were eager to explore the mathematics of path analysis and the logical consequences within networks of sociological variables20. Considered to be one of the first sociological examples of path analysis (Werts & Linn, 1970; Wolfle, 2003)21, Otis Duncan and Robert Hodge wrote “Education and Occupational Mobility: A Regression Analysis” in 1963, a year before Blalock’s work appeared. According to Wolfle, “It occurred to Duncan that what Blalock was attempting to do had already been done by Wright, and Duncan got out his old reprint of Wright (1931) and began to study it carefully" (Wolfle, 1999, p. 280). In interpreting the work of Duncan and Hodge (1963), it will be useful to consider the nature of their sociological variables used in modeling. As mentioned earlier, it is the nature of the system of variables evaluated in terms of presumed causality, and the extent to which assumptions regarding directionality and independence of errors that essentially defines the model suitable for causal deduction. The hypothesized model by Duncan and Hodge is given in Figure 5.
Duncan and Hodge were interested in evaluating potential causes of occupational mobility from a sample of individuals surveyed in 1951. The variables entered into their model included the father’s occupational SES (Fa’s Occ. SES), education, measured in number of years attending school (Educ.), occupational SES in 1940 (1940 Occ. SES), and occupational SES in 1950 (1950 Occ. SES). The authors left little doubt that they considered issues of causation to be separate from the statistical analyses conducted on their data: “The causal paths that we conceive to underlie the statistical associations in the data are suggested by [Figure 5], where the variables are ordered by their assumed temporal sequence” (Duncan and Hodge, 1963, p. 632).

What is especially noteworthy in their path diagram was the direction of “flow” of the presumed causes. Father’s occupational SES was assumed to cause an individual’s educational attainment, as well as occupational SES in the years 1940 and 1950. Additional causal relations were posited from education attainment to SES in both 1940 and 1950. Lastly, one’s occupational SES in 1940 was hypothesized to cause one’s occupational SES in 1950. What is worth noting from this is that the hypothesized direction of causality for each path was relatively easily justified. That is, given a directional hypothesis between father’s occupational SES and occupational SES in 1950, the direction must necessarily be one-way and from father’s SES to SES in 1950. To posit an opposite direction would make little sense in that it would be temporally impossible for one’s SES in 1950 to cause their father’s SES in years previous. Similarly, the relationship between SES in 1940 and SES in 1950 is necessarily one-way, for the same reason that it is temporally impossible for one’s latter SES to cause one’s previous SES. Hence, in the model posited by Duncan and Hodge, a key assumption of causal modeling was satisfied, that of the directionality among variables. Although they had no way of showing that errors were pairwise uncorrelated, the assumption of directionality made their model at least “plausible” in the sense of justifying a causal process. As will be seen later, even though interpreting path models causally, many models posited by psychologists cannot even satisfy this essential assumption of directionality.
Despite the eventual “rediscovery” of path analysis by sociologists in the 1960s, as remarked by Bollen, it is of somewhat surprise that social scientists and statisticians did not fully appreciate Wright’s work sooner. However, once noticed by such sociologists as Blalock and Duncan, the method of path coefficients soon spread to other areas of social and statistical science (Blalock, 1991), including economics and political science. Aside from the exceptional case of Burks’s work in 1928, path-analytic methods were not adopted by psychologists in full until the early 1970s (Werts & Linn, 1970). According to Bollen (1989), the work of Jöreskog (1973), Keesling (1972), and Wiley (1973), in their development of general structural equation models, played a significant role in popularizing path-analytic methods23. Their accomplishment was essentially in combining elements of path analysis, that of the structural relations among a set of variables, with elements of latent variable analyses (e.g., factor analysis). The advent of structural equation modeling as a general framework allowed one to posit directional relations among variables, and could also incorporate unmeasured variables (i.e., factors) in the process of modeling24. Bollen noted that although work on structural equations was nothing new, the work of Jöreskog, Keesling and Wiley provided a more solid foundation for structural equation models:
. . . related work in sociology during the 1960s and early 1970s demonstrated the potential of synthesizing econometric-type models with latent rather than observed variables and psychometric-type measurement models with indicators linked to latent variables. But their approach was by way of examples; they did not establish a general model that could be applied to any specific problems. It awaited the work of Jöreskog (1973), Keesling (1972), and Wiley (1973) for a practical general model to be proposed. (Bollen, 1989, p. 7)
Aside from generating the technical details for a general modeling framework, Jöreskog, along with Sörbom developed the canned computer software LISREL25. The software provided a relatively easy and efficient way for social scientists, including psychologists, to construct and evaluate structural equation models. Bollen claimed that “LISREL software perhaps has been the single greatest factor leading to the spread of these techniques throughout the social sciences” (Bollen 1989, p. 8)26.
The study of history allows one to arrive at conclusions in the present by an informed interpretation of the past. This method of analysis lends itself particularly well to path analysis, for as seen, its historic tie with issues of causation is an interesting one. Stemming from the work of Wright, path analysis was immediately conjoined with causal issues. It would appear that the sociologists who adopted Wright’s methods saw in his work an opportunity to apply a novel method to a host of sociological problems. However, the actual technicalities of these models, such as the work on spurious correlation by Simon, were merely new methods of analyzing patterns of covariances and correlations. Essentially, any claims to the establishment of “causal models” came packaged with such methodologically deep assumptions as to make even the idea of inferring a true causal model seem foolish. Recall the two assumptions required for a causal model. First, the directionality of cause and effect must be hypothesized, without empirical methods to test these hypotheses. Directionality could be somewhat deduced with variables such as age, for instance, in which it is virtually impossible to have circumstances in which I.Q. determines one’s chronological age. Although hypothesizing directionality among certain variables is relatively easy, specifying directionality among other variables can prove extremely difficult, and must rely extensively on theory (i.e., assumptions) for validation. For instance, positing that self-esteem is caused by such things as the quality of mother-child relationships must simply be taken for granted, or at least supported by previous research findings27. After all, it is equally plausible that mother-child relationships cause self-esteem. And, of course, it is also a possibility that neither causes the other. Hence, assumptions of directionality among variables can be granted for only particular types of variables and are extremely difficult to satisfy, if not impossible, with other types. That is to say, as far as the assumption of directionality goes, some models lend themselves more easily to “causal analysis” than do others.
Recall the second assumption that must be satisfied for a model to be considered causal. The system of variables must effectively constitute a “closed reality” in the sense that all causal variables have been identified. That is, given a three-variable model for instance, it must be assumed that there are no other variables in the universe that are correlated pairwise to the errors of variables entered into the model. This assumption is entirely unrealistic, if not wholly a priori false. Hence this proves to be the most significant problem with path analysis interpreted as causal modeling, that of having to assume that all influential variables have been accounted for. It is simply an impossible task, and for this reason alone, most applications of path analysis, powerful method as it may be, should not go by the name of “causal modeling.”
Given the tentative “verdict” on path analysis interpreted as causal modeling, it is interesting to note that an increasingly greater number of writers on structural equation modeling recommend a distinct separation of path-analytic methods from issues of causation and the more general theme of causal modeling (e.g., see Games, 1990). For instance, Kelloway (1998) recommended the jettison of causal claims from the technology of structural equations:
Structural equation models do not assess or ‘prove’ causality any more than the application of any statistical technique conveys information about the causal relations in the data. Although the hypotheses underlying model development may be causal in nature, assessing the fit of a model does not provide a basis for causal inference. . . . conditions for causal inference is more a matter of study design than of statistical technique. (Kelloway, 1998, pp. 8-9).
As implied by Kelloway, structural equation models may be causal in nature, but need not be. This would suggest path analysis and structural equation modeling to be distinct from issues of causation, a fact noted by Wright himself early in the invention of the method. The question that follows from this, of course, is why even associate path analysis models and structural equation models with the language of causation? Indeed, as remarked by Irzik and Meyer, the disassociating of path analysis from causal modeling would leave us with interpretations resembling those of multiple regression:
Wright’s formal methods were the familiar ones of ordinary regression . . . The distinction between path and regression analysis is thus largely a matter of interpretation . . . it rests upon the meaning and function of the path coefficients. (Irzik and Meyer, 1987, p. 500).
Of course, a likely reason why path analysis and structural equation modeling have been historically linked is credit to the substantive context in which path analysis arose in the 1920s with the work of Wright. That is, it is quite likely that the name simply “stuck” with the method, and hence the contextual meaning in which the method arose. Indeed, if all substantive problems were of Wright’s original type, that of inferring an implied causality that was in some sense at least “plausible,” then associating path analysis with names such as causal modeling would not be so harmful and misleading. However, there is much evidence in the social science literature that social scientists, namely psychologists, have mistakenly conflated the method of path analysis with causation. This is a serious error. For instance, titles of the following type are plentiful in the psychological literature: “Causes and effects of teacher conflict inducing attitudes towards pupils: A path analysis model.”28 Such investigations, we argue, mistakenly adopt the substantive meaning of Wright’s path analysis without any theoretical justification. Indeed, even contrary to early sociological analyses in which the temporal order of variables was known, assuming to know the direction of effect between teacher conflict and attitudes towards pupils is at best a methodological nightmare. Add the fact that it is literally impossible to suggest that no other variables are correlated with the errors of both teacher conflict and attitudes, the hypothesizing of a causal model becomes that much more inappropriate. That the mathematics of the model may be correct is not at issue. Indeed, interpreted correctly, path models yield valuable information, that of assessing change in one variable as measured in light of change of other variables. This is not to say that discussions of causality have absolutely no place in designs that are not one hundred percent experimental (e.g., see Fox, 1997). It is to say however that associating what amounts merely to “trivial mathematics” in any way with a causal theme is unjustified.
Perhaps a second reason as to why social scientists are keen on using path analysis as a causal methodology is that some continue to popularize the statistics of path analysis as somehow intertwined with theory. Land (1969) argued that a function of causal modeling is in “bridging the gap between sociological theory on the one hand and the results of classical statistical analysis on the other” (Land, 1969, p. 4). However, one must give pause in encouraging the blending of theory and statistics. To begin with, theoretical issues are not statistical (Anderson & Gerbing, 1988). Underlying the multitude of statistical applications that have been provided by statisticians, there still must be a solid groundwork on which to apply statistical analyses. In this sense, statistics are best interpreted as addressing and evaluating theory rather than in co-existing with them. Although path-analytic models allow one to assess various indirect effects that may be hypothesized in sound theory, this does not imply that theory and statistics should be unified or “bridged” in any way.
In concluding this article, it would do well to evaluate an initial question asked at the beginning, that of whether path analysis and structural equation modeling merit the name of causal modeling. That is, given the study of the historical context in which path analysis arose, and a consideration of its adoption by sociologists, economists, and eventually psychologists, a conclusion on path analysis as a causal methodology will now be attempted.
It would appear that the name of causal modeling arose more out of the context of Sewall Wright’s work and not independent from it. It could be said that despite Wright’s valuable contributions, he may have done well not to identify his method of path coefficients with causal implications, or in any way associate causality in relation to the method. Indeed, one might conjecture that had Sewall Wright not initially believed heredity and environment to be “causal” in determining color transmission, the method of path coefficients may never have been incorrectly interwoven with issues of causality. It is not that Wright was “wrong” in calling his models causal, nor can Duncan and Hodge be considered at fault for identifying their model to be causal, for it was reasonable in each case to assume an underlying causality among variables in their networks. However, the causality implicit in their works had nothing to do with path coefficients, but everything to do with substantive claims about their research. In this sense, the method of path analysis is, as are all statistical tools, simply a calculating machine applied to a substantive problem of theoretical interest. Consider Figure 6 as an aid to illustrating this simple but most important point.
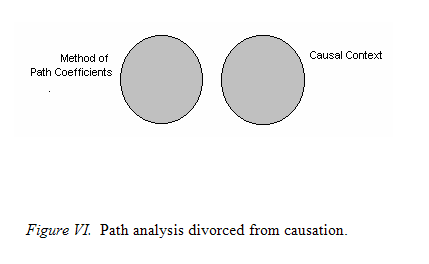
On the left side is the method of path coefficients, on the right side a causal context of a research paradigm. The degree to which the two overlap constitutes a claim for having a causal model. That is, merging the method of path coefficients with that of a causal context makes the case for a causal model more convincing, as shown in Figure 7.
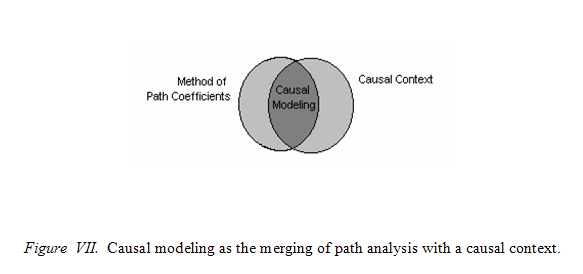
What must be emphasized is that the method of path coefficients should be considered independent of its causal context. Only in the case in which path analysis, or indeed any other statistical procedure is applied to a causal context can the resulting model be considered causal. Indeed, as suggested by Figure 7, one can have good causal models (i.e., a complete overlap) or poor causal models (minimal overlap).
If one thing can be learned from the history of path analysis, it is that statistical methods, powerful as they may be, should take a second seat to the more broad issues of good research design, experimental control, and cautious investigatory practices. As Kenny perhaps said it best, “one cannot take bad data and turn it into gold by calling it a causal model” (Kenny, 1979, p. 8). Statistics add nothing whatever to poor research design and weak experimental practices. All social scientists, including psychologists, need to be occasionally reminded of this.
Anderson, J. C., & Gerbing, D. W. (1988). Structural equation modeling in practice: A review and recommended two-step approach. Psychological Bulletin, 103, 411-423.
Asher, H. B. (1976). Causal modeling. Sage University Paper series on Quantitative Applications in the Social Sciences, 07-003. Beverly Hills and London: Sage Publications.
Bentler, P. M. (1986). Structural modeling and Psychometrika: An historical perspective on growth and achievements. Psychometrika, 51, 35-51.
Blalock, H. M. (1961). Correlation and causality: The multivariate case. Social Forces, 39 , 246-251.
Blalock, H. M. (1964). Causal inferences in nonexperimental research. Chapel Hill: University of North Carolina Press.
Blalock, H. M. (1991). Are there really any constructive alternatives to causal modeling? Sociological Methodology , 21, 325-335.
Bollen, K. (1989). Structural equations with latent variables. New York: Wiley.
Breckler, S. J. (1990). Applications of covariance structure modeling in psychology: Cause for concern? Psychological Bulletin, 107, 260-273.
Burks, B. S. (1928). The relative influence of nature and nurture upon mental development: A comparative study of foster parent-foster child resemblance and true parent-true child resemblance. The Twenty-Seventh Yearbook of the National Society for the Study of Education, 27, 219-316.
Castle, W. E. (1914). The nature of size factors as indicated by a study of correlation. Carnegie Institute of Washington Publications , 196, 51-55.
Davenport , C. B. (1917). Inheritance of stature. Genetics, 2, 313-389.
Desrosières, A. (1998). The politics of large numbers: A history of statistical reasoning. London : Harvard University Press.
Duncan, O. D., & Hodge, R. W. (1963). Education and occupational mobility: A regression analysis. The American Journal of Sociology, 68, 629-644.
Fisher Box, J. (1978). R. A. Fisher: The life of a scientist. New York: John Wiley & Sons.
Fox, J. (1997). Applied regression analysis, linear models, and related methods. London: Sage Publications.
Games, P. A. (1990). Correlation and causation: A logical snafu. Journal of Experimental Education , 58, 239-246.
Goldberger, A. S., & Duncan, O. D. (1973). Structural equation models in the social sciences . New York: Seminar Press.
Hair, J. F., Anderson, R. E., Tatham, R. L., & Black, W. C. (1998). Multivariate data analysis. New Jersey: Prentice Hall.
Heise, D. R. (1969). Problems in path analysis and causal inference. Sociological Methodology , 1, 38-73.
Irzik, G., & Meyer, E. (1987). Causal modeling: New directions for statistical explanation. Philosophy of Science, 54, 495-514.
Johnson, R. A., & Wichern, D. W. (2002). Applied multivariate statistical analysis. New Jersey : Prentice Hall.
Jöreskog, K. G. (1973). A general method for estimating a linear structural equation system. In A. S. Goldberger & O. D. Duncan, (Eds.), Structural Equation Models in the social sciences (pp. 85-112). New York: Academic Press.
Keesling, J. W. (1972). Maximum likelihood approaches to causal analysis. Ph.D. dissertation. Department of Education. New York: Wiley.
Kelloway, E. K. (1998). Using LISREL for structural equation modeling: A researcher’s guide . London: Sage Publications.
Kenny, D. A. (1979). Correlation and causality. New York: Wiley.
Land, K. C. (1969). Principles of path analysis. Sociological Methodology, 1, 3-37.
Leeuw, J. D., Keller, W. J., & Wansbeek, T. (1983). Interfaces between econometrics and psychometrics. Annals of Applied Econometrics, 22, 1-12.
Lewontin, R. C. (1980). Theoretical population genetics in the evolutionary synthesis. In E. Mayr, & W. B. Provine, (Eds.), The evolutionary synthesis: Perspectives on the unification of biology (pp. 58-68). Cambridge: Harvard University Press.
MacCallum, R. C., & Austin, J. T. (2000). Applications of structural equation modeling in psychological research. Annual Review of Psychology, 51, 201-226.
Meehl, P. E., & Waller, N. G. (2002). The path analysis controversy: A new statistical approach to strong appraisal of verisimilitude. Psychological Methods, 7, 283-300.
Mulaik, S. A., & James, L. R. (1995). Objectivity and reasoning in science and structural equation modeling. In R. H. Hoyle, (Ed.), Structural equation modeling: Concepts, issues, and applications (pp. 118-137). London: Sage Publications.
Niles , H. E. (1922). Correlation, causation and Wright’s theory of “path coefficients.” Genetics , 7, 258-273.
Niles , H. E. (1923). The method of path coefficients: An answer to Wright. Genetics, 8, 256-260.
Pearson, K. (1901). On lines and planes of closest fit to a system of points in space. Philosophical Magazine, 2, 559-572.
Pedhazur, E. J. (1982). Multiple regression in behavioral research: Explanation and prediction . New York: Holt, Rinehart and Winston, Inc.
Pedhazur, E. J. (1997). Multiple regression in behavioral research. New York: Wadsworth.
Porter, T. M. (1986). The rise of statistical thinking: 1820-1900. New Jersey: Princeton University Press.
Provine, W. B. (2001). The origins of theoretical population genetics. Chicago: University of Chicago Press.
Sava , F. A. (2002). Causes and effects of teacher conflict inducing attitudes towards pupils: A path analysis model. Teaching and Teacher Education, 18, 1007-1021.
Schumacker, R. E., & Lomax, R. G. (2004). A beginner’s guide to structural equation modeling. New Jersey: Lawrence Erlbaum Associates.
Simon, H. A. (1957). Models of man. New York. Wiley.
Spearman, C. (1904). General intelligence, objectively determined and measured. American Journal of Psychology , 15, 201-293.
Tabachnick, B. G., & Fidell, L. S. (2001). Using multivariate statistics. Boston: Allyn and Bacon.
Werts, C. E., & Linn, R. L. (1970). Path analysis: Psychological examples. Psychological Bulletin , 74, 193-212.
Wiley, D. E. (1973). The identification problem for structural equation models with unmeasured variables. In A. S. Goldberger and O.D. Duncan, (Eds.), Structural equation models in the social sciences (pp. 69-83). New York: Seminar Press.
Wolfle, L. M. (1999). Sewall Wright on the method of path coefficients: An annotated bibliography. Structural Equation Modeling, 6, 280-291.
Wolfle, L. M. (2003). The introduction of path analysis to the social sciences, and some emergent themes: An annotated bibliography. Structural Equation Modeling, 10, 1- 34.
Wright, S. (1918). On the nature of size factors. Genetics, 3, 367-374.
Wright, S. (1920). The relative importance of heredity and environment in determining the piebald pattern of guinea-pigs. Proceedings of the National Academy of Sciences, 6 , 320-332.
Wright, S. (1921). Correlation and causation. Journal of Agricultural Research, 20, 557-585.
Wright, S. (1923). The theory of path coefficients: A reply to Niles’s criticism. Genetics, 8 , 239-255.
Wright, S. (1931). Statistical methods in biology. Journal of the American Statistical Association , 26, 155-163.
Yule, G. U., & Kendall, M. G. (1932). An introduction to the theory of statistics. New York : Hafner Publishing Company.
1. The terms “path analysis” and “method of path coefficients” are used interchangeably throughout this article, and can be considered equivalent in meaning.
2. For the purposes of this article, structural equation modeling is best considered an extension of path analysis. The essential difference between the two is whereas path analysis specifies relations among observed variables, structural equation modeling, in addition, allows for the estimation of latent variables.
3. It is apparently more than mere coincidence that Wright was working with guinea pigs: “Wright always identified himself primarily as a developmental geneticist. He said to me once that the mathematical work was really a diversion from his first love, which was guinea pigs” (Lewontin, 1980, p. 61).
4. This issue, that of ensuring more equations than unknowns, relates to problems of identification. For instance, fitting a line to two points would be considered “just-identified.” These models are also referred to as “saturated” and not surprisingly, always fit perfectly. Fitting a line over several points (i.e., over-identified) is desirable, for it yields a greater number of degrees of freedom. See Bollen (1989) pp. 88-104 for details.
5. Indeed, as is true of any statistical procedure, substantive issues should always be considered independent of the mathematical derivations. For instance, as is sometimes misunderstood, there is nothing inherently “causal” or “experimental” about ANOVA models. Any sense of experimental control must be had before the arithmetic of ANOVA is applied. In this sense, ANOVA, or any other statistical model, is nothing more than a complex calculating algorithm designed to transform numerical data into another form. The calculating machine is blind to the theory you espouse.
6. This is not to say that causality cannot be subsumed in a path model, but only that path analysis, the procedure, has nothing inherently to do with issues of causation.
7. Wright did relax this assumption somewhat later in his career however, and conceded that even if causal relations were not hypothesized, the method of path coefficients could still be successfully applied. The interpretation of the system would of course be different, and would not be deemed causal.
8. Although this appears to be true of statistical texts for the social sciences, in a popular and more rigorous multivariate text, Applied Multivariate Statistical Analysis (Johnson & Wichern, 2002), path analysis and structural equation models are introduced in the context of factor analysis and structured covariance matrices. What is more, issues of causation are not emphasized, stating only that “structural equation models are sets of linear equations used to specify phenomena in terms of their presumed cause-and-effect variables” (Johnson & Wichern, 2002, p. 524). Hence, such a presentation from a more purely statistical point of view serves to support the argument that causal issues are inherently independent from the mathematics of path-analytic models.
9. The study by Burks was funded in part by the Commonwealth Fund, and from grants from the Thomas Welton Stanford Fund for Psychological Research. Although path analysis would be taken up primarily by sociologists by mid-century, the study by Burks was the first post-Wright use of path analysis in psychology.
10. Of course, our evaluation of Burks’s work does not depend on this interpretation. We mention this only to suggest that although causal statements are usually avoided in regression, they are usually the very claims we wish to know by our research.
11. According to Wolfle (2003), Causal inferences in nonexperimental research was one of the most influential publications introducing causal modeling to sociology.
12. As will be seen later, pioneers of causal modeling in the social sciences were even apt to recognize these assumptions, some of which virtually impossible to satisfy, but necessary for path analysis to be considered at all “causal.”
13. Error terms in a path-analytic model are meant to account for influences not explained by the model. For instance, the error associated with X 1 includes all influences, unmeasured, that act upon X 1 but are not included in the estimation of the model.
14. It should be noted of course that simply by concluding that a single third variable does not influence the correlation between X 1 and X 2 cannot in itself be considered as evidential support for a non-spurious relationship, since there are literally an infinite number of spurious correlation hypotheses that could be hypothesized. One would only be able to conclude that the relationship between X 1 and X 2 is not spurious in relation to the third variable tested.
15. For instance, early work by Duncan and Hodge (1963) in which relations such as occupational status in one year were hypothesized to determine occupational status in a later year were quite clear in terms of directionality. That is, given an obvious temporal sequence among variables, or strong theoretical justification for directionality, positing relationships within a path-analytic system proves not as difficult as if these conditions are not so obvious. As remarked by Heise, “there is no error-check mechanism in path analysis to reject an incorrect ordering. . . . The causal laws governing the system are [must be] established sufficiently to specify the causal priorities among variables in a way that is undebatable” (Heise, 1969, pp. 51-52). Indeed, recalling Wright’s early work, the assumption that the make-up of the parent guinea pig causes the genetic make-up of its offspring was relatively obvious in terms of direction.
16. No attempt is here made to distinguish sociologists from “sociometricians.” However, the distinction should be noted. A common popular misperception may be that sociologists are limited in terms of quantitative training. However, the quantitative sociologist, or sociometrician, is usually extensively trained in quantitative methods and can be considered as well-equipped mathematically as the seasoned econometrician or psychometrician.
17. In Blalock (1961), he also discussed how to extend Simon’s notion of spurious correlation to five variables.
18. Blalock also pointed out that even in experimental designs, claims of causality are often preceded by a host of assumptions. Hence, according to him, strong a priori assumptions were necessary for both correlation and experimental designs.
19. In modern path analysis and structural equation modeling, these “third variables” are often referred to as “mediators.”
20. Recall that the deduction of “logical consequences” was suggested as a second alternative interpretation of path coefficients by Sewall Wright should the presumed causes not be fully known. Indeed, it would appear that conflating Wright’s two intended purposes is what has led authors using path analysis and structural equation modeling to make unjustified claims of causality in their research, as will be discussed at the conclusion of this article.
21. Aside from Burks’s 1928 work, it is probably also the first example of path analysis in the social sciences, including psychology. As will be discussed briefly later, psychologists’s adoption of path-analytic models came with the introduction of LISREL by Jöreskog in the 1970s.
22. For a thorough review of structural equation model applications in psychological research, see MacCallum & Austin, 2000.
23. Leeuw, Keller, & Wansbeek (1983), in addition to citing Jöreskog, also credit Goldberger in the creating of a general structural equation modeling framework.
24. Bentler noted the integration of psychometric factor analysis with structural equation models to be “the single most exciting development in structural modeling that occurred during the past quarter century” (Bentler, 1986, p. 41).
25. LISREL is an abbreviation for Linear Structural RELations.
26. That a computer software program helped to popularize a statistical method is hardly surprising. Indeed, the use of statistical methods in general has probably increased exponentially with the advent of computers.
27. It is not known how such directionality in this case could be supported by previous research. The point is simply that if directionality is assumed, there must be some basis for it other than simply the preference of the researcher. What complicates the situation further, as noted by Mulaik and James (1995), is that identical model fit can be achieved by models positing different directions of causality among the same variables. Hence the importance of theoretical considerations in not only structural equation modeling, but of all statistical modeling in general.
28. The article can be found in Sava (2002). See Breckler (1990) for more examples where causal language is used by psychologists performing causal modeling.
Theory & Science